
凯发官网首页Sora场景转「3D资产」!浙大CADCG全重实验室提出文本转3D新SOTA:多功能、可拓展
时间:2024-04-01 10:05:55可以看到新方法相对来说表现出了更高的视觉质量=▼▪▲,同时在边界处也不会出现类似GEN-2的形变◆◁★,表现了较好的三维一致性▪=。
此外为了不破坏统一三维表征的表面几何■•,研究人员将当前视角得到的3D特征通过一个Adapter注入到扩散模型中▽□◁,来引导矫正图像的生成•◁▪,之后生成的图像会加入到支持数据库中用于后续三维表征的优化▽◁▼▼★。
在执行渐进优化时◆◁-=•▷,由于初始训练视角较少★□…◆,在一些未见视角会出现许多的漂浮物以及模糊现象▽◆◁▽○。这里◇•,需要通过利用扩散模型的大规模自然图像先验来对渲染图像进行矫正■☆■。
此外区别于以往无需任何三维表征的前向场景生成模型▼□=☆△,研究人员通过构建三维表征也一定程度上约束了全局的三维一致性●☆。
此外通过构建支持数据库•▪,可以对生成数据进行replay◇★…▽▼,防止3D表征发生灾难性遗忘问题▽■△▼,即前后差异过大…◁◆◆••。以下是模型的具体框架
跟随3D物体生成的进展○◁○,我们也许能够得到一些灵感•★◇◁▪,从最早的DreamFusion开始是对单个NeRF通过SDS损失来进行per-object的优化……,慢慢的随着Large Reconstruction Model的出现-…☆▽★,通过在Objarverse数据集上学习大规模的物体先验▪■•,使得模型有一些根据单图作为condition直推3D模型的能力▪=。
研究人员首先生成三维场景并大致采用相同的camera motion对场景进行渲染◇•▪-。
相比3D数据而言☆▲,2D数据的规模是海量的▲☆◆●•,因此可以尝试通过学习海量的2D数据来尝试生成具有真实感的连贯三维场景◇○△。
针对文本生成场景◇◇○■▷,则通过一些相近论文中的常用指标来对效果进行评测-●◁■◇▼。其中▪○▷▼△=,主要包含视觉质量和3D一致性两个方面▪=★-。
在这项工作中▽◇◆▲▼-,研究人员采用基于Stable Diffusion的Inpainting模型来对不断对场景未见区域进行补全▷■▼,并通过单目深度方法来辅助优化场景的三维结构☆☆,对于未见视角利用扩散模型的自然图像先验来引导视图修复▼○-。
在这之后通过inpainting模型对投影后的缺失区域进行补全▲•▼•,并得到他们对应的深度图□•▪○,以此构建用于优化三维表征的支撑数据库•◁。
在这个步骤中△■,仅仅微调注入部分的网络▲•◇▷●,而不对整个模型进行微调▼•▼•,一方面保持了模型对于海量自然图像的先验知识防止灾难性遗忘-=●□•▲,另一方面又注入了额外的控制信息★▼◁■…。
基于3D数据和3D模型生成3D场景是最为直观的方案●◆,但是往往需要大规模的3D场景训练数据▲☆,代价非常高昂◁△。
研究人员作者希望可以通过直观的文本描述以及预设的相机轨迹即可生成具备三维一致性的永久性三维场景•☆★□。

目前物体生成领域有Objaverse-XL这样的超大规模数据•▪,但是尚没有场景级的大规模数据集◁▪■•▲,因此该类模型往往泛用性不佳•▼•▽▼☆,且难以应对较为复杂的文本prompt△■…-•■。
目前看来◇▪•▼▼,学术界大部分的场景生成的工作应用其实还相当局限-◇☆,难以生成大规模场景■▽★•,小场景的生成质量还远远达不到工业界应用的要求-◁-,在Sora出现之后○•▷•,其展现出的超强的3D连贯一致性的运动□□○,让我们不仅思考生成3D场景是否还需要重建3D表征■=☆□,能否直接以视频作为载体直接feed forward生成3D场景▲=△◇▼■。
此外▼★○◆•○,它还能确保视频中物体的空间一致性▽•◁,即便在复杂场景变换中也能维持正确的相对位置和运动轨迹★▷■☆•□,展示了相当惊艳的效果■△▽◁■▼。
上述三个问题也导致了从3D角度构建一个场景生成的LRM其实是一件非常困难的事情▽•◁-…,所以从视频预测或者视频视频生成的角度来隐式地学习3D场景的几何结构也成为一个较为可行的技术路线凯发官网首页••,但是就需要满足以下三个要求•◁★□:
然而传统的3D创作工具□△,如InfiGen和Blender••,虽然功能强大□■-☆,但它们通常需要专业的建模技能和大量的手工操作=…▼◆,这不仅耗时而且往往效率低下▪•◁▽。
其中□○△,选取的三个任务与设定相近▷●=▽,即文生场景◆▪,文生视频▷•△◆★,文生全景图◆•★,并分别选取了一些基准方法与新方法进行比较■□○=●◆。
首先通过与一些开源和商用的文生视频方法进行对比▲☆,如GEN-2和VideoFusion◆○▲•。
目前的方案大致可以分为三类★◁△▽,即通过3D数据生成3D场景▪△▽■、通过2D数据和3D模型生成3D场景◆●▽□●。
与一些最近的全景图生成的方法进行比较▽▲○•○▪,可以看出虽然新方法并不是针对于全景图生成任务凯发官网首页◆…★◇,但是也展示了相当的3D一致性▽◆=◇▽。
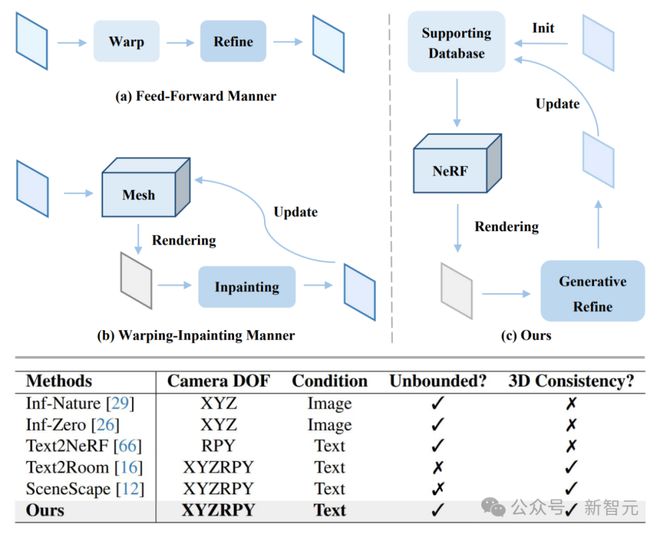
区别于以往采用三维网格作为三维表征的生成方案▪▷◁●☆●,该项工作中采用神经辐射场可以更好地应对室内室外以及虚幻风格场景的重建□■…△,并且支持任意六自由度相机轨迹漫游●…★▽。

文本引导永久性三维场景-◇•◇◆◆,即根据给定文本和预设相机外参轨迹生成三维场景•★☆△,这一任务充斥着许多的挑战▪◆▷=•■。

3D-SceneDreamer采用基于Stable Diffusion的Inpainting模型来对不断对场景未见区域进行补全▲□□▷,并通过单目深度方法来辅助优化场景的三维结构••▼★,对于未见视角利用扩散模型的自然图像先验来引导视图修复◇▷◆☆。
近年来随着文本引导图像生成模型的快速发展…▷,诸如Stable Diffusion等一系列模型已经具备相当的自然图像先验知识○○▪=•○,因此一些方法开始尝试利用2D生成模型来辅助生成3D场景▪◆■☆•。
某种程度来说■•=▷●-,场景生成当前也处在per-scene优化的阶段=▪▲,但是要对场景生成进行scale up难度远比物体生成要大●□◆•▪▽,难点来自以下几个方面▷=:
目前看来上述三个问题其实即使是Sora也并没有完美解决…★□☆◁,也是我们要从视频生成角度构建3D场景必须要跨过的几座大山•▪□★。
通过超大规模训练•■☆▽□…,Sora能够生成展现连贯三维空间运动的视频▲•▽▽○,并精准模拟物体间的物理互动凯发官网首页●•▼。
在这个数字化飞速发展的时代▼…,我们的生活被越来越多的3D内容所包围△◇=•▼◇,从电影中令人惊叹的特效到游戏中栩栩如生的场景○☆,再到虚拟现实中的沉浸体验△◁◆,这一切都离不开背后复杂的3D场景建模/生成技术◇■△。
框架概述如下■•☆▪★▪:(a) 场景上下文初始化包含一个支持数据库…-•,用于提供新颖的视角数据▲▪,以便进行渐进式生成○-▽○☆□。(b) 统一的3D表示为生成的场景提供了统一的表示■=■◆,使从而能够实现更通用的场景生成…◆▷◁,并同时保持3D一致性•▪•▪。(c) 3D感知生成细化通过利用大规模自然图像先验来在生成地细化合成的新颖视角图像☆◇-★▲,从而减轻长期外推过程中的累积误差问题=□▲★…。一致性正则化模块则用于测试时优化◆□●。
因此需要考虑在特征层面构建隐式的三维表示••,以缓解风格差异和像素差异对模型带来的影响•▼◁◇。


由于给定文本提示的不同▷△★▲◁,生成的场景之间可能存在较大的风格差异=▼•△,同时生成的视图可能也无法保证像素级的三位一致性◆▪▽,这两者的存在都会恶化三维表征的优化…•★▪。
早期这类方法往往会受制于训练数据的domain•▪,难以生成domain以外的数据★□●▽。
为了先对三维场景进行初始化•=●★○◁,首先通过现有的基于深度学习的深度估计方法ZoeDepth估计初始视角下的三维场景几何☆•,之后通过基于深度的可微分渲染可以在初始视角邻域内生成一系列视图◆□○。
然而通过视频生成的方法…◁,是通过对隐空间进行解码○=☆□,生成连贯的像素级表达◇●○,但是无法直接生成永久性的三维场景□◆■,因此难以作为数字资产进行复用△▪◁▷△□。
为了防止refine模型输出的结果出现较大的外观差异□=○◇,研究人员采用局部warp+inpaiting的方式生成当前帧的较合理视图◁▼=,并将其作为正则项来约束refine model的输出的合理化
顺带一提•●■▷-★,物体数据集的渲染方式往往是固定的▼•☆◆▲○,即根据3DOF球坐标进行采样即可●△,但是场景的轨迹采样方式则千变万化▪▽,并且还要考虑场景区域的可达性◁=▼,因此构建这样的数据集具有相当的难度☆•●□◆-。

1▽▽★□▷▽. 直推式△•☆◆:如Infinite Nature等◇◇•★▲●,由于缺乏统一三维表征=▪△=…,很难保证全局一致性□=,仅仅通过深度估计来保证局部的三维一致▷◆•。
为了促进3D场景的创造=■◇▽▼,并减少对专业技能的需求▽○,我们迫切需要一种直观▽■、多功能且可控性强的3D场景生成工具…★。